










I’ve been toying with writing an application that would be a review engine of sorts. This would be useful on my headphone review site www.headphonereviewhq.com and I have ideas of other places I could use this. It would also allow me to do some meaningful coding that I could use for examples on this site so it’s a win-win-win situation. In thinking of this design though, I’ve been trying to come up with a flexible database design that would work without creating massive amounts of overhead to manage. So, let’s get started with my thoughts…
So here’s one direction that could be taken that is very flexible, but definitely not geared towards performance and creating an end-user interface (not the administrative) might be a little challenging:
 Product Attribute Schema
Product Attribute Schema
So it’s easy to see from this that in our ProductType table, we might have a few different things such as:
- Over Ear Headphones
- In Ear Headphones
- On Ear Headphones
- Portable Headphone Amplifier
Now, looking at these examples above, it’s not unreasonable to think that there might be some attributes that would be shared between the various types – for instance, on ear headphones and over ear headphones could both have pad material, and both could have an attribute for replaceable cables. Looking at the diagram I used here, you wouldn’t be able to share those attributes. So maybe we need to revise this design a bit…
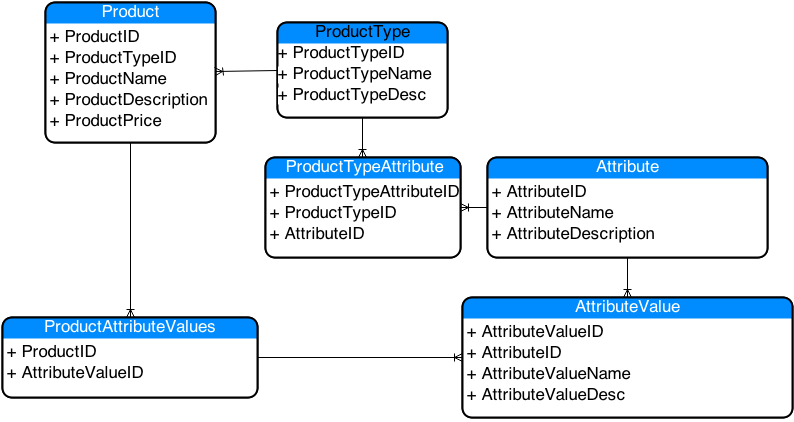 Now able to share attributes between Product Types
Now able to share attributes between Product Types
Now we can see that we could share Attributes between different types. Our Over Ear Headphones and On Ear Headphone types could now both use the same Attribute “Ear Pad Material”. But, now this brings up another problem! What if we had types that were perfectly fine to be shared but the Values themselves didn’t work well from one type to another? Well, it looks like we’ll need to modify our schema again to allow us to lock down the values by product type and not just the attribute….
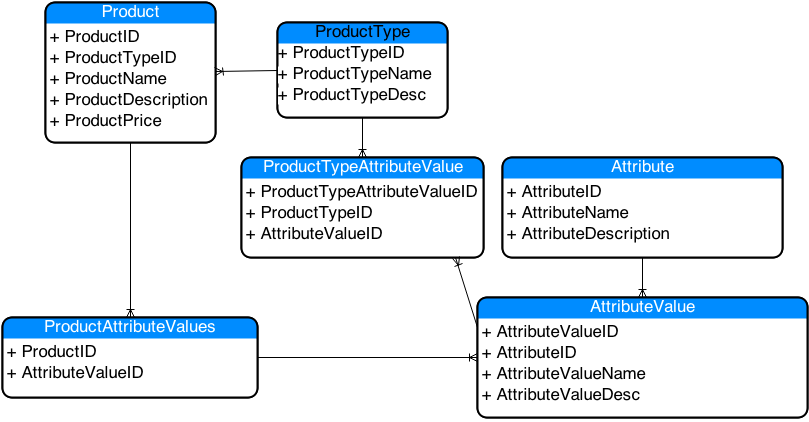 Most Flexible Product Attribute Schema
Most Flexible Product Attribute Schema
So, now we can see that we’ve got an extremely flexible schema. Following with the example from above, let’s say we’re going with the On Ear/In Ear/Over Ear example, and let’s say that we have an attribute called “Driver Technology”. For all types of headphones, “Dynamic” would be a perfectly suitable value, but “Orthodynamic” would only be available for over ear. Likewise, “Balanced Armature” would only be valid for In Ear headphones. Now that we’ve separated the values out, this is now achievable and would be fairly easy to set up via an administrative interface. In order to enforce the data integrity at the ProductAttributeValues table, we’d probably want to put a check constraint in there to ensure that only products with a valid ProductTypeID can choose a given AttributeValueID.
Again, admin interface on this wouldn’t be too difficult. I can think of a number of ways to put this together, and I may actually do that in the future, but let’s continue with this particular database problem before I go diving into the UI.
Now that we’ve got a very flexible, and normalized database design, it would appear that we’re in pretty good shape to move forward….
There’s a couple of things to consider before we get ahead of ourselves.
PERFORMANCE / SEARCHABLE
The biggest problem with this setup is that we will end up with an extremely “vertical” set of data once information on products is filled out – what do I mean by vertical? All the information on a product will be stored in multiple rows. If you end up with a thousand products in your database and you have 40 attributes per product, then you’re looking at 40,000 records. Not a lot and any modern RDBMS can handle that kind of load with the appropriate indexes and tuning, however, when you grow to 10,000 products, you’re now into 400,000 attributes to maintain. Again, not a ridiculous amount for most databases, but you can see that scaling may become a problem at some point and the last thing you want is your database getting bogged down just trying to retrieve and update catalog information.
Performance Grade: C
One of the fantastic things about this particular schema layout is that because you’re storing everything in a normalized fashion, you would literally have one of the cleanest sets of data available for filtering down your result sets. This is an extremely positive thing. One of the biggest problems most people face after building a catalog repository of some time is that there is a lot of bad data that needs to be scrubbed repeatedly to get something SOMEWHAT useable for searching/filtering.
Searchable Grade: A
ADMIN INTERFACE
Being that the data is very normalized in this particular database layout, writing an administrative interface for this type of schema would actually be pretty easy and would scale with very little additional work in the future. Remember, normalized database structure ALMOST always equals an easier to maintain administrative interface.
Admin Interface Grade: A
END-USER INTERFACE
One of the other major problems I see with this particular setup is how we’re going to display this information back to the user. If we’re looking at headphones, we’d likely want to have the information come back in some sort of standard, consistent manner. In the current design we have no way to manage that. What if we added a sequence to at least bring the data back in a particular order? I don’t think we’d want to do this at the ProductAttributeValue level because then you’d have to make sure all your On Ear Headphone products have the exact same sequencing, and if you ever wanted to update the sequence for the entire group, you’d have to write some fairly complex SQL scripts to accomplish the task. No, you’d probably want to do this at the ProductTypeAttribute level…so let’s see what that looks like:
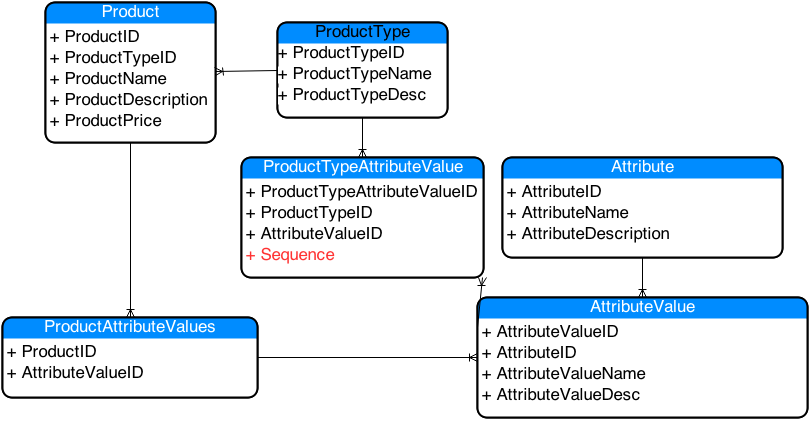
Ordering of Attributes
Now that the sequence is in there, we can see for a given Product Type and a given Attribute, we can now sort the data by the Sequence column in our queries. This will help us get a bit further along but will require a fairly sophisticated templating system in our application to display the information properly. Other than performance mentioned above, I believe the output interface (what the end user would see), would be the biggest challenge with this layout. Especially if you consider that this may contain things other than just headphones. Maybe you have dozens of types of products and each is going to have its own set of attributes and values. This could get very complicated very fast. Keep in mind that this information would be coming back to the application in a long row format – not in a single record. Granted, you could do some SQL wizardry and pivot the data, but then the queries will have to be intimately aware of the Product Types, Attributes and Values in order to do the correct pivot or transformation. Like I said before – this could get pretty hairy – either at the database level or at the application level, or both.
End-User Interface Grade: C (complex system)
Another way this COULD be approached is to have a different ProductType table for each type defined.
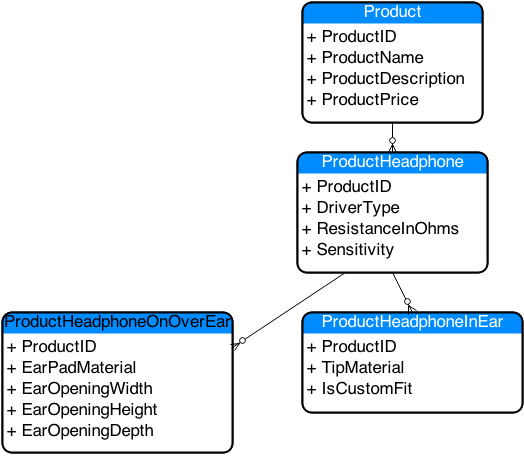
Separate Product Type Entities
Now this is a very explicit type of database design with its own merits. Here we can clearly see what the attributes of each type of headphone is. No need to write queries to join together attribute tables to value tables back to the product. No, you can simply do a select * from ProductHeadphoneInEar and get a list of all the in ear headphones and all the pertinent attributes.
PERFORMANCE / SEARCHABLE
The performance of this type of layout will be excellent. Your tables can be indexed appropriately and adding/retrieving data will be fast as it will be on a single row. Again, querying the data can be sped up easily with the appropriate indexes and tuning. This is a huge plus for this type of setup.
Performance Grade: A – Easily retrieve a single record for a product with simple joins
As far as for searching this information – this would all depend on whether you made the attributes values in external lookup tables. If you didn’t then search could become the nightmare I mentioned in the previous database schema. Any time you let people key enter items freely for each product, you’re going to back yourself into a corner when it comes to data integrity and normalization. Just to reiterate, that can be avoided with this layout as well just making sure most fields are lookups to other tables.
Searchable Grade: B – can be excellent if data in columns is chosen via lookup tables
ADMIN INTERFACE
Whereas the normalized schema would have a fairly easy administrative user interface, the schema where there’s a table for each type will be fairly difficult to create and maintain. Any time there’s a new attribute added to a table, it’s very likely someone will need to update the administrative pages for managing the products. Any time a new type is created, you’ll have to create another administrative page. You may be able to accomplish some of this through generating some code templates, but the problem still stands that the interface will need to change each time the underlying tables change.
Admin Interface Grade: D
USER INTERFACE
The user interface would be slightly easier to implement simply because you have well defined parameters as to what each product type is. Similar to the admin interface, if you add a database column, you would modify your template for that type. Every time you add a new column to the table you’ll need to touch your application code as well to keep things up to date. In the flexible model mentioned at the beginning of the article, you could basically create a dynamic template that would grow with the data. There are pro’s and con’s to each method.
User Interface Grade: C
MAINTAINABILITY
This is where this particular structure really suffers. If you’re only maintaining a handful of product types, then this is fine. If you have hundreds of types of products you’re maintaining, this can really become a problem over time. The number of CRUD operations that would need to be maintained would grow linearly with the number of tables, or you’d have to come up with a sophisticated way of maintaining all the products via an application user interface. Also, retrieving data could become tricky. Now you’d need to determine product types and be able to dynamically move your way through all the tables unless you are planning on writing get procs/queries for each and every product type. Again, this can turn into a bit of a maintenance problem.
Maintainability Grade: D
Conclusion
I hate to call this a conclusion because I’m just getting started. I’ve not settled on how I’m going to do this as of yet. I’m even toying with going to a NoSQL solution as you can basically just define your records for each product independent of each other. Really all that’s needed in a NoSQL record is the key and whatever attributes you want to tack onto the record. Not saying this is great design and I can definitely see some major downfalls with this approach as well, but it’s worth taking a look.
I’d really love to hear any thoughts you guys/gals have on this. I personally like the scalable solution (the abstract tables) but I would likely build some denormalized tables to mimic the 2nd solution for performance sake. If nothing else, I hope this sparks some thought and some good conversation.
